
VOO a achevé Memento, son programme de transformation Business Intelligence et Big Data avec, à la clef, une migration cloud. Découvrez comment Micropole a accompagné l’opérateur belge au cours des différentes phases du projet.
Les défis & enjeux de VOO
Dans le cadre d’une transformation globale, Micropole a accompagné l’opérateur belge VOO dans la transformation complète de ses services de Business Intelligence, de son environnement Big Data et IA, et dans sa migration vers le cloud. Cette migration était essentielle pour répondre à des besoins opérationnels stratégiques et urgents, notamment :
- Augmenter significativement la connaissance client pour accélérer l’acquisition et améliorer la fidélisation
- Accompagner la transformation numérique en offrant une vision unique du client et de son comportement
- Répondre aux nouveaux défis liés à la conformité (RGPD)
- Réduire drastiquement le coût total de possession (TCO) des environnements de données (4 environnements BI différents + 3 clusters Hadoop avant la transformation)
- Mettre en place une gouvernance des données à l’échelle de l’entreprise et traiter le surcoût de la “shadow-BI” : plus de 25 ETP comptabilisés dans les équipes métiers pour faire du data crunching.
Les solutions & les résultats générés par Micropole
Micropole a mené une courte étude afin d’analyser tous les aspects de la transformation, en abordant à la fois les défis organisationnels (rôles et responsabilités, équipes et compétences, processus, gouvernance) et les défis techniques (scénarios architecturaux holistiques, allant du cloud hybride aux solutions cloud complètes en mode PaaS).
Sur la base des résultats de cette étude, Micropole a déployé une plateforme de données basée sur le cloud à l’échelle de l’entreprise, qui combine les processus traditionnels de Business Intelligence avec des capacités analytiques de haut niveau.
Micropole a contribué à redéfinir l’organisation des données et les processus associés, et a introduit la gouvernance des données dans toute l’entreprise.
Le TCO a été réduit de 70% alors que l’agilité et les capacités de traitement et d’idéation se sont considérablement améliorées.
Une architecture basée sur les services de données clefs d’AWS
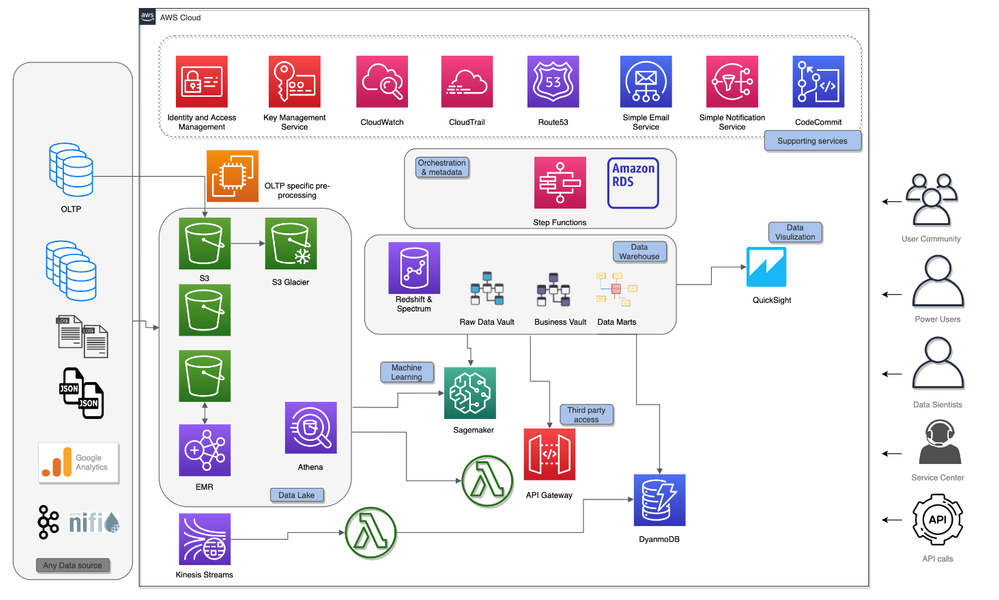
Data lake
Amazon S3 est utilisé pour la couche centrale d’ingestion et permet d’assurer une persistance à long terme.
Certains fichiers de données sont préparés sur Amazon EMR. Les clusters EMR sont créés à la volée plusieurs fois par jour. Les clusters ne traitent que les nouvelles données entrantes sur S3. Une fois que les données sont traitées et conservées dans un format Apache Parquet optimisé pour l’analyse, le cluster est détruit. Le chiffrement et la gestion du cycle de vie sont activés sur la plupart des buckets S3 pour répondre aux exigences de sécurité et de rentabilité. Plus de 600 To de données sont actuellement stockées dans le Data Lake. Amazon Athena est utilisé pour créer et maintenir un catalogue de données et explorer les données brutes dans le Data Lake.
Ingestion en temps réel
Amazon Kinesis Data Streams capture les données en temps réel, qui sont filtrées et enrichies par une fonction Lambda avec les données du Data Warehouse, avant d’être stockées dans une base Amazon DynamoDB. Les données en temps réel sont également stockées dans des buckets S3 dédiés pour la persistance.
Data Warehouse
Le Data Warehouse tourne sur Amazon Redshift, en utilisant les nouveaux nœuds RA3 et suivant la méthodologie de modélisation Data Vault 2.0. Les objets Data Vault sont très normalisés et ont des règles de modélisation strictes, permettant ainsi un haut niveau de standardisation et d’automatisation du Data Warehouse. Le modèle de données est généré depuis les métadonnées stockées dans une base Amazon RDS Aurora.
Le moteur d’automatisation est lui-même construit sur Apache Airflow, déployé sur des instances EC2.
La mise en œuvre du projet a commencé en juin 2017 ; le cluster de production Redshift initialement dimensionné sur 6 nœuds DC2 a évolué de manière transparente au fil du temps et a constamment répondu aux besoins croissants du projet en matière de Data, et a répondu à toutes les attentes métiers.
DynamoDB
Amazon DynamoDB est utilisé pour des cas spécifiques, lorsque les applications Web nécessitent des temps de réponse très inférieurs à la seconde. L’utilisation de la capacité de lecture/écriture de DynamoDB permet de fournir une capacité de lecture exceptionnelle, mais également plus onéreuse, qui est ainsi utilisée seulement pendant les heures ouvrables du service, lorsqu’une faible latence et un temps de réponse instantané sont requis. Ces mécanismes, qui reposent sur la flexibilité des services AWS, permettent d’optimiser la facture mensuelle AWS.
Machine Learning
Une série de modèles prédictifs a été mise en œuvre, allant d’un modèle de prédiction d’attrition classique à des cas d’usage plus avancés. Par exemple, un modèle a été judicieusement conçu pour repérer les clients susceptibles d’être affectés par une panne de réseau. Amazon SageMaker a été utilisé pour créer, former et déployer les modèles à grande échelle, en tirant parti des données disponibles dans le Data Lake (Amazon S3) et le Data Warehouse (Amazon Redshift).
Un accès externe aux API
Pour des besoins de regulation, des acteurs externes doivent accéder à des sets de données spécifiques, de manière sécurisée, traçable et fiable. Amazon API Gateway est utilisé pour déployer des API REST sécurisées, en plus des microservices de données serverless implémentés avec des fonctions Lambda.
Et bien plus encore !
La plateforme de données que Micropole a construit pour VOO offre beaucoup d’autres possibilités. La palette très riche des services disponibles sur l’environnement AWS permet chaque jour, de traiter de nouveaux cas d’usage de manière rapide et efficace.


